种质资源库李德铢团队在植物馆藏标本基因组浅层测序研究方法上取得重要进展
来源:中国西南野生生物种质资源库 作者:曾春霞 2018-06-13 浏览次数:
世界上约3400个植物标本馆,目前收集标本数量总计超过三亿五千万份(http://sweetgum.nybg.org/science/ih/)。这些标本馆几乎收集了当地分布的所有物种,加起来大体上覆盖世界上已知植物物种。馆藏标本经过分类鉴定,蕴含着丰富的物种信息,其中模式标本更是每个物种科学名词(学名)的直接承载者。由于植物材料特性、干燥条件、储藏时间等因素的影响,标本DNA高度降解,DNA提取浓度低,且易受外源DNA 污染。这给标本DNA的提取、目的片段的PCR扩增和Sanger测序带来了较大困难。尽管标本存在较大潜在研究和应用价值,但是标本遗传信息获取技术明显滞后。
中国西南野生生物种质资源库植物多样性与基因组学团队的李德铢团队和分子生物学实验中心多年来一直致力于植物DNA条形码与基因组学研究。新一代测序技术(Next Generation Sequencing)为标本遗传信息的获取带来了新的契机,因为新一代测序技术正是以100-400 bp的短片段分子为建库模板。同时,基因组浅层测序(Genome Skimming)通过二代测序技术获得全基因组较低测序深度基因组数据,借助于生物信息学手段,可得到叶绿体全基因组、线粒体全部或者部分基因组,以及核基因组中高度重复区域(如rDNA)等序列数据。最近,该团队曾春霞博士在分子生物学实验中心团队的支持下,与爱丁堡皇家植物园合作,综合考虑标本的完整性、稀缺性和不可替代性,尝试选择500 pg的起始DNA(文献报道多以ng或μg为起始量),通过文库构建流程的优化,成功获得标本的叶绿体全基因组和rDNA序列数据,用于DNA条形码2.0和系统发育基因组学研究。
研究发现,以500 pg为起始量,通过模板分子不打断;不做片段选择;不少于8个PCR循环富集barcode文库,可以作为低质量样品文库构建的标准流程。对25份标本(采集时间为1934-2007年不等)进行测试,23份标本可以获得完整或几近完整的叶绿体基因组序列,21份标本可以获得rDNA序列。目前,分子生物学实验中心已经形成低质量样品文库构建的标准与技术规范,以及数据组装和拼接规范。基于标本获取叶绿体全基因组和rDNA序列数据的技术,应用前景广泛,包括(1)可用于DNA高度降解的各类植物制品(如木材、树皮、粉末、中草药、饮片等),以及植物根系、动物消化物等的物种鉴定;(2)将模式标本的遗传信息整合到现有分类框架中;(3)从标本获得现已无法采集或甚至野外灭绝物种的遗传信息;(4)获取标本遗传信息用于评估环境变化等导致的遗传多样性丧失或变化。
研究成果以“Genome skimming herbarium specimens for DNA barcoding and phylogenomics”为题发表于植物学研究方法的国际期刊Plant Methods上。该研究得到了科技基础性工作专项重点项目(2013FY112600);中国科学院重大科技基础设施开放研究项目(2017-LSF-GBOWS-02)和中国科学院战略生物资源服务网络计划生物多样性保护策略项目(ZSSD-011)的资助。
文章链接:https://link.springer.com/article/10.1186/s13007-018-0300-0
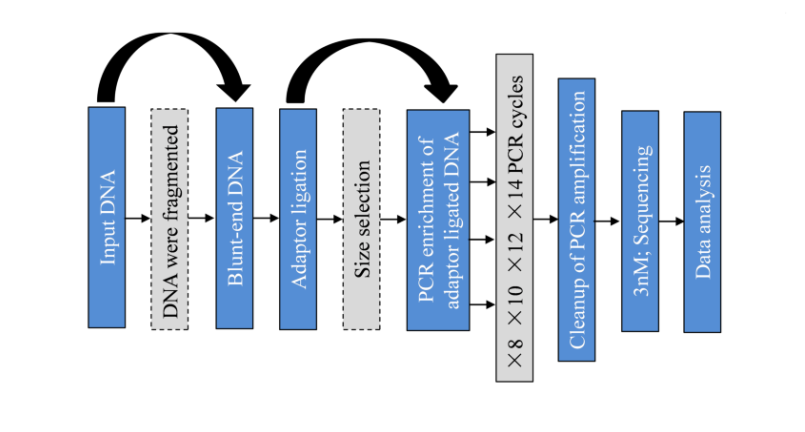
文库构建流程图